When you ask ChatGPT a question, unlock your phone with your face, or get a recommendation from Netflix, you're interacting with neural networks. These systems power almost everything we now call "AI." But how do they actually work?
This guide breaks down neural networks explained in terms anyone can understand. No computer science degree required. No math anxiety necessary. By the end, you'll know exactly what's happening under the hood of the AI tools you use every day.
Understanding AI and machine learning fundamentals starts here.
What Is a Neural Network, Really?
A neural network is a type of computing system that learns from examples rather than following explicit instructions.
Traditional software works like a recipe: "If this happens, do that." A programmer writes every rule. But with artificial neural networks, you show the system thousands (or millions) of examples, and it figures out the patterns on its own.
The "neural" part comes from a loose inspiration: the human brain. Your brain contains roughly 86 billion neurons connected by trillions of synapses. When you learn something new, those connections strengthen or weaken based on experience.
Artificial neural networks mimic this idea—but they're not actually brains. They're math. Lots of it. The good news? You don't need to understand the math to understand the concept.
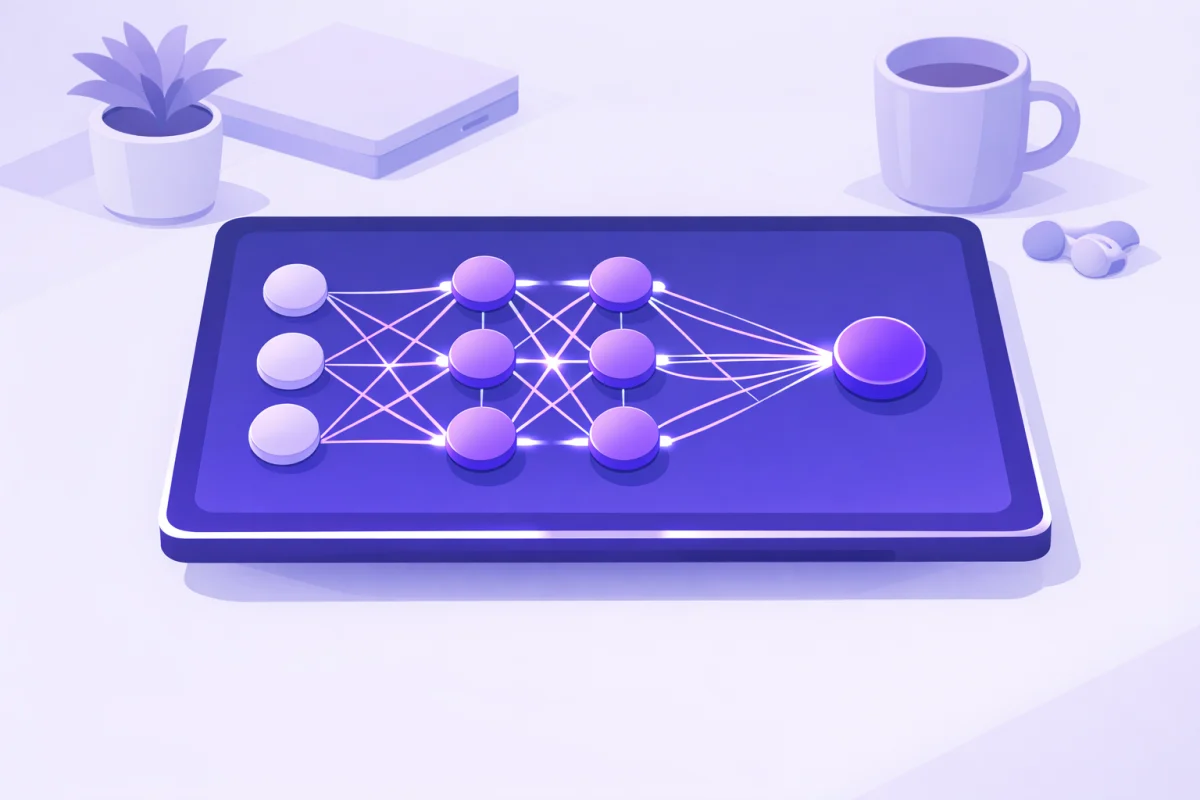
How Neural Networks Work: The Basic Architecture
Every neural network has three main components:
Input Layer
This is where data enters the system. If you're building a network to recognize handwritten digits, each pixel of the image becomes an input. A 28×28 pixel image means 784 inputs.
Hidden Layers
These middle layers do the actual "thinking." Each layer transforms the data, looking for increasingly complex patterns. The first layer might detect edges. The next might detect shapes. A later layer might recognize that those shapes form the number "7."
The more hidden layers a network has, the "deeper" it is. That's where the term deep learning comes from.
Output Layer
This produces the final result—a classification, a prediction, or generated content.
The Building Blocks: Neurons, Weights, and Biases
Understanding neural network basics means understanding how information flows through the system.
Neurons (Nodes)
Each neuron receives input, does some simple math, and passes the result forward. Think of neurons as tiny decision-makers. On their own, they're not very smart. But connected together in layers, they can solve incredibly complex problems.
Weights
Weights determine how much influence one neuron has on another. A high weight means "pay attention to this connection." A low weight means "mostly ignore this." When a neural network learns, it's really just adjusting these weights.
Biases
Biases help neurons activate at the right times. They're like a threshold that says "don't fire until the signal is strong enough."
If you want a deeper understanding of how model parameters and weights work, these concepts are foundational.
Activation Functions
After receiving weighted inputs, each neuron applies an activation function to determine its output. Common ones include ReLU (which outputs zero for negative values and the value itself for positive ones) and sigmoid (which squishes everything between 0 and 1).
These functions introduce non-linearity—the property that lets neural networks learn complex, curved patterns instead of just straight lines.
How Neural Networks Learn: Forward Pass and Backpropagation
Here's where things get interesting. Neural networks don't come pre-programmed with knowledge. They learn through a process that's surprisingly similar to how humans learn from mistakes.
Step 1: Forward Pass
Data flows through the network from input to output. The network makes a prediction. At first, this prediction is essentially random because the weights start at arbitrary values.
Step 2: Calculate the Error
The network compares its prediction to the correct answer. The difference is called the "loss" or "error." A network that predicted "cat" when the image showed a dog has a high error.
Step 3: Backpropagation
This is the clever part. The network works backward through its layers, figuring out which weights contributed most to the error. Then it nudges those weights in the direction that would reduce the mistake.
Step 4: Repeat
This process repeats thousands or millions of times across thousands or millions of examples. With each cycle, the weights get a little better. The predictions get more accurate. The network learns.
The whole process is powered by machine learning—giving computers the ability to improve through experience rather than explicit programming.
Types of Neural Networks: Different Tools for Different Jobs
Not all neural networks are built the same. Different architectures excel at different tasks.
Feedforward Neural Networks (FNN)
The simplest type. Data flows in one direction—input to output—with no loops. Good for basic classification and regression tasks. Think of predicting house prices based on square footage and location.
Convolutional Neural Networks (CNN)
Designed for visual data. CNNs use filters that slide across images, detecting features like edges, textures, and shapes. They're behind facial recognition, medical image analysis, and the filters in your photo apps.
A CNN for image classification might have layers that:
- Detect edges and basic shapes
- Combine those into more complex patterns
- Recognize objects like "car," "dog," or "stop sign"
Recurrent Neural Networks (RNN)
Built for sequential data—anything where order matters. Text, speech, time series, music. RNNs have loops that let information persist, giving them a kind of memory.
But basic RNNs struggle with long sequences. By the time they reach the end of a paragraph, they've forgotten the beginning.
Long Short-Term Memory (LSTM)
An improved version of RNNs that can remember information over longer sequences. LSTMs were essential for early speech recognition and machine translation systems.
Transformers
The architecture behind modern AI. Transformers don't process data sequentially like RNNs. Instead, they use attention mechanisms to consider all parts of an input simultaneously and figure out which parts are most relevant.
This parallel processing makes transformers faster to train and better at capturing relationships across long documents. The "T" in GPT stands for "Transformer."
ChatGPT, Claude, Google's Gemini—they're all transformer-based. So are DALL-E and Midjourney for image generation.
ANN Explained Simply: A Real-World Example
Let's walk through how a neural network might learn to classify emails as "spam" or "not spam."
The Training Data
You gather thousands of emails, each labeled as spam or legitimate. These become your training examples.
Feature Extraction
The network receives information about each email: word frequency, presence of certain phrases ("Click here!"), sender reputation, link count, and so on. Each feature becomes an input.
The Learning Process
Initially, the network guesses randomly. Maybe it predicts "spam" for an email from your boss. That's wrong—high error.
Through backpropagation, it learns that emails with "FREE MONEY" in the subject line are usually spam, while emails from contacts in your address book usually aren't. It adjusts weights accordingly.
After millions of examples, the network becomes quite good at distinguishing spam. It's learned patterns no programmer explicitly coded.
Neural Networks in Modern AI Applications
Neural networks aren't just theoretical—they're everywhere.
Language Models
ChatGPT runs on a neural network with billions of parameters. It was trained on massive amounts of text, learning to predict what word comes next. That simple objective, scaled up enormously, produces surprisingly coherent and useful responses.
Vision language models extend this to understand both images and text together—like being able to describe what's in a photo or answer questions about visual content.
Image Recognition
Facebook uses CNNs to tag your friends in photos. Google Photos searches your library by content. Medical systems detect tumors in X-rays and MRIs. Self-driving cars identify pedestrians, lane markings, and traffic signs.
Voice Assistants
Siri, Alexa, and Google Assistant use neural networks for speech recognition (converting your voice to text) and natural language understanding (figuring out what you actually want).
Recommendation Systems
Netflix suggests what to watch. Spotify creates personalized playlists. Amazon predicts what you might buy. All powered by neural networks analyzing your behavior and finding patterns across millions of users.
Code Generation
GitHub Copilot and similar AI tools for coding assistance use transformer networks trained on code repositories. They predict what code you're likely to write next, offering suggestions as you type.
Why Neural Networks Work (And Sometimes Don't)
Neural networks are remarkable because they can learn patterns that would be impossible for humans to specify manually. No programmer could write rules to recognize every possible handwritten "7" or every way to phrase a question.
But they're not magic, and they have real limitations:
They Need Data
Lots of it. A neural network can only learn patterns that appear in its training data. Show it only black and white photos, and it won't understand color. Train it only on English text, and it won't speak French.
They Can Be Fooled
Adding imperceptible noise to an image can make a neural network confidently misclassify it. These "adversarial examples" reveal that networks don't "see" the way humans do.
They're Black Boxes
With millions or billions of parameters, it's often impossible to explain why a network made a particular decision. This matters a lot when neural networks are used in healthcare, criminal justice, or finance.
They Learn Biases
If the training data contains biases (and it usually does), the network learns those biases. A facial recognition system trained mostly on one demographic will perform worse on others.
They Require Significant Computing Power
Training large neural networks demands specialized hardware (GPUs or TPUs) and substantial energy. Running them at scale isn't cheap.
A Brief History: How We Got Here
The idea of neural networks isn't new. Warren McCulloch and Walter Pitts proposed the first mathematical model of a neuron in 1943. Frank Rosenblatt built the Perceptron—an early neural network—in 1958.
Progress stalled in the 1970s and 80s. Neural networks were slow, required data that didn't exist, and couldn't compete with other approaches.
Everything changed with three developments:
- More Data: The internet generated unprecedented amounts of text, images, and video.
- More Computing Power: GPUs made it possible to train much larger networks.
- Better Algorithms: Techniques like backpropagation became practical and effective.
In 2012, a neural network called AlexNet won an image recognition competition by a huge margin. That victory kicked off the deep learning revolution we're still living through.
Common Questions About Neural Networks
Are neural networks the same as AI?
Not exactly. AI is the broad goal of creating intelligent machines. Neural networks are one technique for achieving that goal—currently the most successful one for many tasks.
Do neural networks think like humans?
No. Despite the "neural" name, these systems don't think, understand, or experience consciousness. They're pattern-matching machines—incredibly sophisticated pattern-matching machines, but not minds.
How big are modern neural networks?
ChatGPT's GPT-4 is estimated to have over a trillion parameters. That's roughly 10 times more than the synapses in a human brain, though the comparison is imperfect.
Can I train my own neural network?
Yes! Tools like TensorFlow, PyTorch, and Keras make it accessible. Many tutorials start with the MNIST dataset—handwritten digits. With a basic laptop, you can train a network that recognizes digits with 98%+ accuracy in under an hour.
What's the difference between a neural network and deep learning?
Deep learning is neural networks with many layers. A "shallow" network might have one hidden layer. A "deep" network might have dozens or hundreds. Depth allows the network to learn more abstract, hierarchical patterns.
What's Next for Neural Networks?
Research moves fast, but a few directions are clear:
Efficiency: Making networks smaller and faster without sacrificing performance. "Distillation" techniques compress huge models into versions that run on phones.
Multimodal Models: Systems that understand text, images, audio, and video together. GPT-4 can already process both text and images.
Reasoning: Current models are excellent at pattern matching but struggle with multi-step reasoning. New architectures aim to improve logical thinking.
Interpretability: As neural networks make more consequential decisions, understanding why they decide what they decide becomes critical.
Customization: Fine-tuning large models for specific domains—legal, medical, financial—is becoming easier and more common.
Ready to explore what neural networks can do for you? Browse the AI tool directory to find specialized tools for your specific needs—whether that's writing, coding, image generation, or data analysis.
The Bottom Line
Neural networks have gone from a theoretical curiosity to the technology behind the most powerful AI systems ever built. They learn from data, recognize patterns humans could never specify, and power everything from spam filters to language models that pass bar exams.
Understanding neural network basics doesn't require a PhD. At their core, these systems are about inputs, weighted connections, and learning from mistakes—concepts anyone can grasp.
What makes them extraordinary isn't complexity for complexity's sake. It's that relatively simple principles, applied at massive scale, can produce behavior that looks remarkably intelligent.
The AI tools you use today—and the ones you'll use tomorrow—almost certainly run on neural networks. Now you know what's actually happening when you interact with them.


